DevoxxFR 2012 ~ Retours

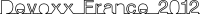 ~ J'y étais!
~ J'y étais!
Tout d'abord il convient d'adresser un grand merci et un grand bravo aux organisateurs et aux équipes techniques. Un super évènement très dense!
Voici un retour sur les conférences auxquelles j'ai pu assister pendant deux jours. Toutes les conférences ayant été enregistrées, je ne saurais que trop vous conseiller de les voir ou revoir sur Parleys dès qu'elles seront disponibles.
Jeudi
[Keynotes]
Après un rappel - chargé d'émotion pour les organisateurs - sur la génèse de Devoxx France par Antonio Goncalvez (@agoncal), la keynote suivante me laisse perplexe.
"Fier d'être développeur?" par Pierre Pezziardi

Peut être que je n'étais pas très bien reveillé mais je n'ai pas du tout réussi à entrer dans le contenu de cette présentation. Je trouvais très difficile de voir où voulait en venir M. Pezziardi, j'avais plus l'impression d'un discours décousu et un patchwork d'idées (qui mérite d'être creusées!) livrées pelle-mêle.
Je suis fier d'être développeur mais je ne me suis pas trouvé dans cette conférence et après reflexion je n'étais dans le bon état d'esprit: cette présentation est tirée de son livre "Lean Management". Le titre reflète très bien le contenu de cette présentation contrairement à "Proud to be a developer".
Ceci dit j'ai investi dans ce livre afin de "revoir" cette présentation avec un autre angle.

"This could be Heaven or this could be Hell"

Un super show de Ben Evans & Martijn Verburg! (@kittylyst & @karianna) sur ce qui pourrait arriver de mieux (ou de pire!) à Java. Un vrai spectacle à voir ne serait-ce que pour réaliser que rien n'est tracé et que tout peux changer: developpeur investissez-vous et donnez rapidement vos retours sur les prochaines évolutions de la JVM.

[Conf] ElasticSearch: moteur de recherche NoSQL/REST/JSON
Tout part du constat qu'une recherche textuelle en SQL voit son temps d'execution dégénéré lorsque les tables dépassent les 500k lignes:
select document_id from documents where text like '%devoxx%'.
Compte tenu des volumes impliqués il est alors nécessaire d'avoir une solution de recherche plus poussée. Elle doit intégrer à la fois :
- l'indexation des données pour une recherche performante
- la gestion de gros volume de données via un mode distribué: ce qui implique réplication des données sur plusieurs noeuds, sharding, tolerance au panne, montée en charge par ajout de resource...
- une gestion souple des différents modèles de document
"Pas évident à trouver un truc comme ça" vous allez me dire!
Imaginez Lucene avec une interface REST et un support complet pour le mode distribué! Hummmm je vous sens interessés mais dubitatifs!: "ça doit être drolement compliqué à installer et configurer!".
Imaginez une application que vous téléchargez et sans configuration vous avez tout ça prêt à l'emploi: perplexe?
Et bien c'est pourtant le constat qu'a fait David Pilato (@dadoonet) en découvrant ElasticSearch et qu'il nous livre à travers cette présentation aussi claire, fluide et simple que le produit qu'il présente.
N.B.: si vous ne connaissez pas Lucene autrement que par son nom, je vous conseille la présentation "Recherche d'information" à laquelle j'ai assisté vendredi.
Toutes les interactions se font par requête HTTP+Json, pas d'interface utilisateur sexy: c'est un moteur! On peux donc tout faire par simple ligne de commande (par exemple via curl).
Des urls de type REST permettent très simplement de définir le typage de nos données, l'espace logique auquels elles appartiennent (index) et les actions que l'on souhaite effectuer: création, suppression, recherche, etc.

Il est ensuite assez simple de naviguer à travers nos données à la manière d'un drill-down en définissant les "facettes" lors des requêtes. Ces facettes ressemblent aux "group by" que l'on trouverait sur une base de type SQL.
PS: la présentation était tellement simple que le lundi d'après, mon client ne jurait plus que par cela, et voulait absolument que l'on fasse quelques POC (Proof Of Concept) pour nos cas d'utilisations.
La présentation Elasticsearch pour #devoxxfr est disponible sur slideshare slideshare.net/dadoonet/elast…
— David Pilato (@dadoonet) Avril 20, 2012 
[Conf] NodeJS and Javascript Everywhere
Une belle présentation de NodeJS avec du codage en direct d'un serveur proxy en une vingtaine de ligne de javascript et une pincée de texan par Matthew Eernisse (@mde)!
Le dernier slide "Try it; you'll like it" résume très bien l'impression que l'on a en ressortant, quand bien même je regarde NodeJS depuis plusieurs mois déjà!
Plusieurs bonnes pratiques pour la gestion de l'asynchronisme et des erreurs innérantes, en vrac: uncaughtException handler et preemptive timeout afin d'informer l'utilisateur si une erreur à eu lieu.
// un garde fou est programmé afin que l'utilisateur
// ait un retour en moins de 600ms quoiqu'il arrive
// comme la baleine bleu de Twitter
// pas plus de 600ms pour avoir un retour sinon on génère une erreur 500.
var timeout = 600;
var handler = setTimeout(function() {
var errorCode = 500;
response.writeHead(errorCode, "Oops something bad happened");
}, timeout);
...
// si tout va bien on annule notre garde fous
clearTimeout(handler);
[Conf] Client/Server Apps with HTML5 and Java
Une chouette présentation par James Ward (@_JamesWard) sur ce que devrait être les applications Web modernes. Cette presentation est une introduction au framework play et à une approche de type WOA (Web Oriented Architecture): stateless, restful et asynchrone.
Le discours tourne autour d'une idée fondamentale: "The browser as an application platform". Il est désormais important d'exploiter au maximum les possibilités du navigateur et de placer beaucoup plus de logique sur celui-ci, de nombreux framework javascript intégrent déjà ces notions
Enfin, James Ward nous parle de webjar dont le but est d'exploiter maven pour la distribution des librairies javascript.

[Quickie] C'est si simple GIT
Une présentation très (trop!) rapide de quelques possibilités de GIT à travers l'utilisation de plusieurs repositories: un central et deux développeurs. Les développeurs n'ont pas les droits de commit sur le repository central et doivent donc propager (push) leurs commits, qui seront ensuite intégrer par l'administrateur.
La présentation nous montre comme il est facile pour un développeur de partager sa branche de travail directement sur le repository de son collègue, travailler ensemble sur la résolution d'un bug au travers de plusieurs commits. Puis finallement de les fusionner (squash) en un seul et unique commit, de le pousser sur le repository central, et permettre au responsable de l'intégrer au répository central après vérification.
On regrettera l'utilisation abusive d'alias, de 'clear console' empêchant d'observer les résultats, et le côté schizophrène de la console qui joue tour à tour les trois rôles: les deux dev. et le responsable. Il est nécessaire de connaitre un peu GIT au préalable pour bien apprécier cette présentation.
Mon Quickie "C'est si simple GIT !" à Devoxx France 2012 disponible sur #github github.com/ulrich/devoxx_… #devoxxfr
— ulrich (@ulrich) Avril 22, 2012
[Conf] DevOps : pas que pour gérer des serveurs
Un retour d'experience sur l'installation de poste de formation par Jerome Bernard (@jeromebernard). Jerome nous présente sa problématique: installer automatiquement des dizaines de postes de formation automatiquement afin d'avoir les environements et les logiciels nécessaires pour chaque type de formation, mais aussi pour les consultants en inter-contrat. Les postes étant "mal-traités" par les formations, il est nécessaire de permettre de les réinitializer avant chaque début de formation.
Plusieurs solutions ont été évoqués et celle retenue consiste à installer sur chaque poste des machines virtuelles Virtual Box. Ces machines virtuelles sont disponibles sur le réseau et automatiquement propagées sur chacun des postes. Les machines virtuelles sont alors lancées et automatiquement installées et configurées en fonction de leurs propres paramètres.
Un serveur Chef est responsable d'installer sur chaque machine Virtual Box. La machine virtuelle à utiliser est quant à elle installée et déployée par Vagrant. Ensuite la machine virtuelle elle-même dispose de sa propre installation de Chef (en mode solo) pour se configurer et se mettre à jour.
Comme chaque machine virtuelle se réinstalle, il important aussi de disposer de mirroirs pour éviter de surcharger la bande passante, ainsi les installations téléchargent directement depuis un serveur interne, et la connexion internet n'est pas saturée.
De très bonnes idées pour mettre en place automatiquement des environements d'intégration continue impliquant de configuration variée de base de données, de serveur d'application, etc.
Mes slides de la présentation #DevoxxFR sur le DevOps pour autre chose que des serveurs sont en ligne : jerome-bernard.com/blog/2012/04/2…
— Jerome Bernard (@jeromebernard) Avril 20, 2012
[Conf] Behind the Scenes of Day-To-Day Software Development at Google
Hummmm... leurré l'aura de Google... une présentation assez decevante de Petra Cross (@petracross du fonctionement des équipes de développements chez Google. Après un rappel de la philosophie Google Ten things we know to be true On enchaine avec les différents postes hierarchiques et casquettes que l'on peut être amené à porter: les Team Leader, Product Manager, ... Les équipes ne sont jamais vraiment figées, mais constitué à chaque projet en prenant des gens à gauche à droite en fonction des besoins du projet; un teamleader est un développeur comme les autres avec des meetings en plus (charge supplémentaire de préparation des Stories...)
Beaucoup de temps passé sur la présentation des méthodes: waterfall, spirale et agile. Pour finalement dire que Google fait un mix des trois, et encore que chaque équipe décide un peu de son fonctionement propre. On retrouve quand même une forte empreinte de scrum: itération courte, story évaluée en points, découpage en tâches, poker planning, ...
- Pas de daily standup meeting! Ca ne sert à rien puisque tout est déjà écrit sur le tableau des tâches: ce qu'il reste à faire, ce qui est en cours et ce qui est fait.
- Les tâches à faire sont priorisées et il faut obligatoirement prendre celle du-dessus, la plus prioritaire, mettre son nom dessus et la changer de colonne.
- Toutes les tâches qui pourraient arriver en cours d'itération sont placées dans le "glaçon" avec un "oui-oui t'inquiètes on la met là et dès qu'on aura du temps on le traitera". Ce qui n'arrive généralement jamais compte-tenu de la rêgle 2.
- pas de retrospective après les chaque itérations, mais toutes les 2 ou 3 itérations
Enfin quelques éléments intéressant (dernier 1/4h) pour le chiffrage des stories lors des Poker planning. En cas de désaccord - supposons que les chiffrages soient 2,2,3,8 - seule une personne de chaque extrême (une pour les 2 et celle du 8) a le droit de parler en suivant une formulation bien précise indiquant les étapes identifiées pour faire la tâche: "Pour faire X, il faut faire a,b et c". Une fois que les deux personnes se sont exprimés, second tour de vote. Si un désaccord subsiste, il est alors possible de poser des questions mais là aussi en suivant des rêgles strictes: * les questions doivent être uniquement binaires (oui ou non) ou à choix multiples; * les questions ne doivent pas contenir d'éléments émotionnels pouvant influencer les réponses: par exemple "c'est pas trop difficle de faire ça?" est interdit
En bref, les développeurs développent et expédient au plus vite toutes les autres tâches et les interactions humaines...

[Conf] Pour un développement durable
Dernière conférence de la journée, par Frederic Dubois, elle ne m'a pas laissé de souvenirs marquant, je regarde mes notes: le logo de la conduite accompagnée... le développeur doit se prendre en main et doit être valoriser dans l'entreprise, il doit être "Fier d'être développeur".

Vendredi
[Keynote] Abstraction distraction
Juste à temps pour la keynote de Neal Ford (@neal4d): à voir absolument! et pas que les développeurs.
Abstraction Distractions: les slides
[Conf] Web Oriented Architecture, une transmutation des pratiques de construction des SI
La WOA par Habib Guergachi (@hguergachi: wahoooooo! quel show! 55min de spectacle ponctué par de nombreux applaudissements. C'est quoi l'avenir des applications? certainement pas les appels synchrones et l'approche RPC et stateful. Il y a trois solutions pour construire la prochaine application: construire avec les briques du passé, construire avec les briques de maintenant une application qui sera dépassée en sortant, ou finalement constuire le futur avec les technologies de demain.
JEE est obsolète! Les mentalités doivent changer, l'avenir est à la WOA: HTML + URI + HTTP. Les applications doivent être asynchrones, RESTful et stateless. Et surtout, il faut être ... relax! "la relaxation temporelle"! Il faut découper les applications en fournisseur de ressources. Lorsqu'une ressource est fournie, les ressources liées sont identifiées par leur URI. On découvre aussi un nouvel accronyme HATEOAS.
Au final, on retrouve tous les concepts distillés dans les principes REST (voir Thèse de Roy T. Fielding - Traduction du Chapitre 5 : REST et Restful Web Services) mis en spectacle, vivant, drôle et surtout accessible!
[Conf] Hibernate OGM: JPA pour NoSQL
Après un rappel sur les différents types de base NoSQL, Emmanuel Bernard (http://twitter.com/#!/emmanuelbernard) nous présent Hibernate OGM: un projet en cours de développement permettant de réutiliser les annotations JPA pour construire une représentation adaptée au stockage NoSQL utilisé. Un exemple bluffant ou juste en changeant les paramètres de persistance, la même application tourne indifférement avec une base de données, Infinispan ou MongoDB.
Hibernate OGM définit un ensemble de mapping équivalent selon le système de persistence sous-jacent, en créant par exemple des enregistrements pour toutes relations entre entités.
Un projet qui me laisse dubitatif:
- avec Hibernate, l'utilisateur est maître de son schema de base de données, et configure ses entités afin de les faire correspondre aux tables sous-jacentes alors qu'Hibernate OGM décide du format de stockage et de sa représentation dans la base NoSQL.
- on réutilise les mêmes annotations pour des paradigmes de stockage bien différents, et le risque d'avoir un modèle non adapté et non optimisé peut être grande.
Un projet à suivre mais qui risque d'être rapidement dépassé par des solutions spécifiques à chaque type de base NoSQL et intégrant leurs spécificités comme les fonctions de recherches ou la création d'index.
[Conf] Recherche d’information (RI) : Fondements et illustration avec Apache Lucene
Comment marche un moteur de recherche d'information comme Lucene? C'est ce que nous propose de découvrir Majirus Fansi à travers un survol très clair et parfois en chanson! des méthodes d'indexation.
Cela commence par une présentation des différents termes et modèles utilisés pour la recherche d'information:
- modèle booléans
- modèle vectoriels: utilisé entre autre par Lucene
- modèle probabilistique (juste évoqué)
On enchaine ensuite sur les différentes étapes de construction d'un index inversé:
- décomposition du texte en mot
- suppression des mots vide de sens (
Stop word) commede,la,les, ...; on prendra garde à sélectionner cesstop wordsen prenant en compte le contexte du texte:ladans un texte musicale n'est pas forcément vide de sens. On pourra remarquer que le plus souvent ces mots seront ceux qui sont le plus référencés par l'ensemble des textes, analyser le nombre d'occurence peux donc être un moyen de les identifier. - les mots sont ensuites transformés dans leur forme générique, lème ou terme:
chevaux->cheval,détruit->détruire... (c'est à ce stade que les moteurs intégrant de la recherche sémantique peuvent ramener le mot à ses catégories sémantiques: cheval, équestre, animal, mamifère...) - l'index inversé est alors généré comme une
Multimapjava: le mot sert de clé et l'identifiant du document est ajouté à la liste des documents référançant ce mot.
Une petite illustration de tout cela, en prenant deux documents:
Depuis sa création, Arolla s’est engagé résolument dans une démarche écologique.
Notre société est zéro carbone : chaque année, nous établissons un bilan précis de notre impact environnemental et le compensons en plantant des arbres... une charte écologique qui vous engage à des gestes quotidiens plus respectueux de l’environnement.
Index inversé:
| Terme | Documents |
|---|---|
| Arolla | 1 |
| engagement | 1, 2 |
| démarche | 1 |
| charte | 2 |
| écologie | 1, 2 |
| environnement | 2 (2fois) |
Nous voyons ensuite comment est calculé la pertinance d'un document pour une recherche: le scoring.
Une fois tous les documents récupérés grâce à l'index inversé, les logarithmes et formules mathématiques sortent de l'ombre... uh! On retiendra qu'il s'agit d'un mélange de "plus un terme est présent dans les documents moins il est informatif", les "mots recherchés apparaissant peu souvent auront un poid beaucoup plus important" dans le calcul de la pertinance: s'il apparait peu globalement et en plus dans un seul document, alors celui-ci aura un niveau de pertinance plus important. Voila en gros l'idée, les logarithmes font ensuite le reste pour lisser et pondérer le tout.
Enfin, nous voyons le modèle vectoriel et comment il intervient dans le calcul de la pertinance. Considérons que l'ensemble des N termes de notre index inversé est un espace vectoriel de dimension N. Chaque document et notre recherche peux alors y être représenté comme un vecteur dont les coordonnées seront par exemple le nombre d'occurence de chaque terme. Un peu confus tout ça? une petite illustration alors!
Voici notre espace vectoriel:
| Terme | Dimension |
|---|---|
| Arolla | 1 |
| engagement | 2 |
| démarche | 3 |
| charte | 4 |
| écologique | 5 |
| environnement | 6 |
Dans cet espace, notre premier document aura les coordonnées suivantes:
d1 = [1, 1, 1, 0, 1, 0]
le second document aura alors les coordonnées suivantes:
d2 = [0, 1, 0, 1, 1, 2]
Une recherche avec engagement écologique et environnement aura les coordonnées suivantes:
r = [0, 1, 0, 0, 1, 1]
En considérant que chaque coordonnées est équivalent à un vecteur partant de l'origine, l'angle entre un document et le vecteur de recherche peux s'écrire: cos(d1,r) = (d1.r) / (|d1||r|) où . dénote le produit scalaire entre deux vecteurs et |x| correspondant à la norme du vecteur x, autrement dit sa longueur.
Voir ici pour plus de détail sur les formules évoquées et utilisées par Lucene.
Cette valeur comprise (en valeur absolue) entre 0 et 1 permet alors de pondérer la pertinance calculée précédement par "l'alignement du document avec la recherche". Si les deux vecteurs sont parfaitement alignés c'est à dire colinéaires cette valeur sera égale à 1. Le poids ne sera donc pas diminué. En revanche si les vecteurs ne sont pas alignés, cette valeur diminuera vers zéro, et la pertinance sera réduite.
La suite de la présentation sera l'illustration de tout cela avec Lucene.
En bref, une présentation très claire des techniques d'indexation. On regrettera la lecture mot à mot des transparents et les grosses équations qui n'apportent pas grand chose au propos sinon de faire décrocher un peu l'auditoire.
Obésiciel et impact environnemental : Green Patterns appliqués à Java
Voila un sujet bien atypique dans une tel conférence, ma fibre verte vibre et je me lance: Obésiciel et Green patterns par Olivier Philippot (@greencodelab). Olivier Philippot commance par demander combien de personne mesure la consommation de leur machine chez eux... personnes, erf! Après quelques constats sur la consommation de l'IT dans le monde (l'infrastructure de Facebook consomme autant qu'un TGV à pleine vitesse, les calculs nécessaires pour le film du Chat Potté ont consommés autant que la planète entière pendant 20min, NDR: oubliez la recursivité!).
Comment se fait-il que sans rien faire son ordinateur me met à consommer de plus en plus, comment explique-t-on cette derive: c'est l’obésiciel ou bloatware. Les logiciels installés consomment de plus en plus de ressources, laissent des processus résidents et consomment de l'espace disque, alors que l'on ne s'en sert probablement même plus. Ce à quoi on répond par des machines de plus en plus puissante et des disques durs de plus en plus gros, et l'on consomme donc de plus en plus.
Comment se fait-il qu'un onglet Chrome qui n'est pas affiché continue de consommer autant, pourquoi une application minimisée continue-t-elle de prendre des ressources... A-t-on besoin de prendre des Timers aussi rapides pour nos applications, ce qui ne permet pas au processeur de se mettre en veille: il ne fait que se reveiller et s'arrêter...
Un très bon résumé chez Soat.
En bref, un sujet atypique, beaucoup de constats, mais peu de solutions concretes, à suivre... Je vais me plonger dans le livre Green Patterns - Manuel d'éco-conception des logiciels afin d'approfondir un peu plus le sujet.
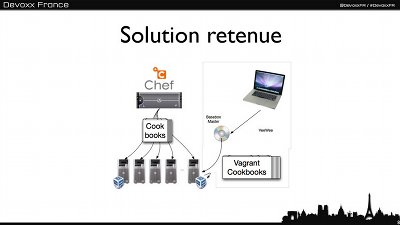
.Net pour le développeur Java : une source d'inspiration ?

Un survol rapide de nombreux sucres syntaxiques et des possibilités de .Net par Cyrille Martraire (http://twitter.com/#!/cyriux) et Rui Carvalho (http://twitter.com/#!/rhuy):
- synthétique
- drôle
- instructifs
- des transparents très esthétique
On retiendra que même si Monsieur M. a initialiement beaucoup copié Monsieur S., Monsieur M. a depuis bien avancé et même pris une sérieuse avance depuis la version 3 de C# en enrichissant énormément les possibilités offertes:
- définition rapide des accesseurs de propriétés (
getetset) - classes anonymes typées! qui permet de créer des structures intermédiaires fortement typées sans avoir à créer une classe dédiée juste pour faire passe plat
- closure
- intégration de Linq: permettant d'intégrer un language de requêtage directement dans le code (comme du SQL) mais s'appliquant aussi bien à des sources de type bases de données qu'à des collections en mémoire d'objet.
- ...
Allez java t'a du retard là!!
CQRS
Et pour clore cet évènement: Mon coup de coeur! CQRS (Command Query Request Segregation) par Jérémie Chassaing (@thinkb4coding.
Une présentation et des explications très claires et fluides par un passionné sur un sujet qui mérite vraiment d'être creusé!

La présentation commence par évoquer les architectures actuelles en empilements de couches (type lasagne), on l'on traverse successivement les couches: Controlleur -> Service -> DAO -> ORM -> base de données; puis l'on revient: base de données -> ORM -> DAO -> Service -> Controlleur. On se rend compte qu'à chaque couche, les données subissent des chaines de transformations uniquement pour passer de notre utilisateur à notre espace de persistance. Que ce soit pour une simple consultation ou pour une mise à jour de données, la succession des couches est identiques; alors qu'une mise à jour nécessite une intégrité fonctionnelle, une simple consultation de données passe par un requêtage complexe avec plusieurs jointures et projection afin d'adapter notre modèle transactionnel à un modèle de consultation. D'autant plus que généralement, 90% des requêtes utilisateurs seront des consultations pour seulement 10% de modifications (une observation générale qu'il convient d'ajuster selon le domaine métier).
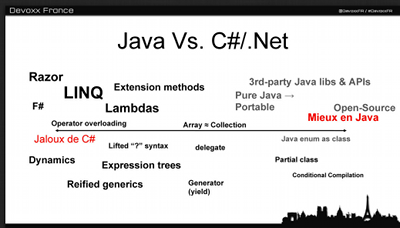
C'est de ce constat que l'architecture CQRS émerge: pourquoi ne pas séparer notre modèle d'écriture (utilisé pour les mises à jour: en écriture seule Write Only) de notre modèle de lecture (utilisé pour les consultations, en lecture seule Read Only): "Deux modèles pour deux besoins"!
Le modèle de lecture est mis à jour en réaction aux notifications envoyées par le modèle d'écriture lors de changements.
Notre modèle d'écriture sera alors optimisé pour l'écriture et contiendra l'ensemble de nos rêgles métier. On pourra privilégier une approche de type DDD (Domain Driven Design) afin de bien refleter les concepts métiers et de facilité la gestion des contours de transaction.
Notre modèle de lecture quant à lui sera optimisé pour la lecture en effectuant toutes les projections préalables et fournir directement les données requises. On pourra par exemple avoir directement une table dédiée à chaque page de notre application, les informations pourront être directement dénormalisées, plus de jointures complexes : se contenter alors d'un select * from table pour la récupération des données
Comme chaque modèle est séparé, il est possible d'adopter pour chacun des stratégies de stockage, de réplication et d'intégrités différentes. On pourra par exemple addresser la montée en charge différement en optant pour du sharding pour les requêtes d'écriture et de la réplication/load balancing pour les requêtes de lecture.
J'ai beaucoup aimé l'aspect non dogmatique et progressif de la mise en oeuvre avec de nombreuses pistes évoquées:
- Partant du constat qu'il s'agit uniquement de décorréler modèle d'écriture et modèle de lecture, il est tout à fait possible de commencer simplement en créant une vue des tables existantes:
create view list_users as select * from users. Au fur et à mesure les besoins de lectures et d'écritures pourront alors diverger de manière transparente. - il est tout à fait possible d'adopter ce motif architectural à un sous ensemble: il n'est pas requis que l'ensemble de l'application applique ce motif.
- la mise à jour du modèle de lecture peux très bien être synchrone au départ puis évoluer vers des approches de type "eventually consistent"
- ...
C'est une présentation que je recommande de voir ou de revoir!
Présentation CQRS à DevoxxFr slideshare.net/jeremiechassai… via @slideshare
— Jérémie Chassaing (@thinkb4coding) Avril 21, 2012 
Conclusion
Deux jours très intenses et franchement à revivre: très riches, très denses et très instructifs.
Quelques mais: des pauses entre chaque conférence peut être trop courte compte-tenu de certains changement de salles et la nécessité de faire des pauses techniques. L'accès des salles Seine A,B,C étaient difficile au milieu des stands partenaires.
On se retrouve pour Devoxx France 2013!


